|
Hanbyul (Han) Joo
|
|


I am an assistant professor at Seoul National University (SNU) in the Department of Computer Science and Engineering. Before joining SNU, I was a Research Scientist at Facebook AI Research (FAIR), Menlo Park. I finished my Ph.D. in the Robotics Institute at Carnegie Mellon University, where I worked with Yaser Sheikh. During my PhD, I interned at Facebook Reality Labs, Pittsburgh (Summer and Fall, 2017) and Disney Research Zurich (Summer, 2015). I received my M.S. in EE and B.S. in CS at KAIST, Korea. I am a recipient of the Samsung Scholarship and the CVPR Best Student Paper Award in 2018.
NEW I am hiring research intern students. See more details here.
Research
The goal of my research is to endow machines and robots with the ability to perceive and understand human behaviors in 3D. Ultimately, I dream to build an AI system that can behave like humans in new environments and can interact with humans using a broad channel of nonverbal signals (kinesic signals or body languages). I pursue this direction by creating new tools in computer vision, machine learning, and computer graphics.
| The Panoptic Studio |
SNU ParaHome |
News
-
Oct 2025 I was awarded the Okawa Research Grant
-
Aug 2025 I will serve as an area chair for ICLR 2026, 3DV2026, and as a lead area chair for CVPR 2026
-
Aug 2025 I gave talks in Arirang TV: The Evolution of AI and AI: Reading Humans
-
Jul 2025 I will be giving a talk in CORL 2025 workshop: Human to Robot (H2R)
-
Jun 2025 I am co-organizing a RSS workshop on Dexterous Manipulation: Learning and Control with Diverse Data
-
May 2025 I will be giving talks in CVPR 2025 workshops: Global 3D Human Poses Workshop, 3D Humans Workshop, and Agents in Interactions, from Humans to Robots
-
Mar 2025 I will be giving a talk in an ICRA workshop: From Computer Vision-based Motion Tracking to Wearable Assistive Robot Control
-
Jan 2025 I will serve as an area chair for CVPR 2025, ICCV 2025, and NeurIPS 2025
-
Aug 2024 The full version of ParaHome DB is now publicly available: [Code/Dataset].
-
Jul 2024 I am co-organizing a workshop on "Artificial Social Intelligence" in conjunction with ECCV 2024
-
Jul 2024 I will be giving a talk in the Observing and Understanding Hands in Action workshop in conjunction with ECCV 2024
-
Jul 2024 Our COMa got accepted to ECCV 2024 as an oral publication
-
Jun 2024 I will be giving a talk in the EgoMotion workshop in conjunction with CVPR 2024
-
Jun 2024 I am co-organizing a workshop on "Virtual Try-On" in conjunction with CVPR 2024
-
May 2024 I serve as an area chair for NeurIPS 2024
-
Apr 2024 I will be giving a talk in the RSS workshop on Dexterous Manipulation: The talk video is available here
-
Mar 2024 My students Jiye and Byungjun will start their internships in Codec Avatars Lab, Meta (Pittsburgh). Congrats!
-
Feb 2024 Four papers got accepted in CVPR 2024
-
Feb 2024 Congratulations to Yonwoo for earning an MS degree!
-
Jan 2024 We have introduced our new multi-camera system: SNU ParaHome
-
Jan 2024 I serve as an area chair for CVPR 2024
-
Jul 2023 Four papers got accepted in ICCV 2023 (including two oral publications)
-
May 2023 I am co-organizing a workshop on "Artificial Social Intelligence" in conjunction with ICCV 2023
-
May 2023 I serve as an area chair for CVPR 2023, ICCV 2023, NeurIPS 2023, WACV 2023
Students
| Subin Jeon (Postdoc) |
| Byungjun Kim (MS/PhD) |
| Jeonghwan Kim (MS/PhD) |
| Hyunsoo Cha (MS/PhD) |
| Jisoo Kim (MS/PhD) |
| Taeksoo Kim (MS/PhD) |
| Inhee Lee (MS/PhD) |
| Sangwon Baik (MS/PhD) |
| Jeonghyeon Na (MS) |
| Hyeonwoo Kim (MS/PhD) |
| Mingi Choi (MS/PhD) |
| Junyoung Lee (MS) |
| Kyungwon Cho (MS/PhD) |
| Gunhee Kim (MS/PhD) |
| Wonjung Woo (MS/PhD) |
| Jongbin Lim (MS/PhD) |
| Siyoung Nam (MS/PhD) |
| Sookwan Han (Intern) |
| Taeyun Ha (Intern) |
Alumni
| Yonwoo Choi (MS) |
| Sungjae Park (Intern) |
Dataset/Library

|
|

|
|

|
|

|
Tutorial

|
DIY A Multiview Camera System: Panoptic Studio Teardown
|
Publications
|
Dexterous World Models
Byungjun Kim*, Taeksoo Kim*, Junyoung Lee, Hanbyul Joo In preprint 2025 [Paper] [Project Page] |
|
|
Hand-Aware Egocentric Motion Reconstruction with Sequence-Level Context
Kyungwon Cho, Hanbyul Joo In preprint 2025 [Paper] [Project Page] |
|
|
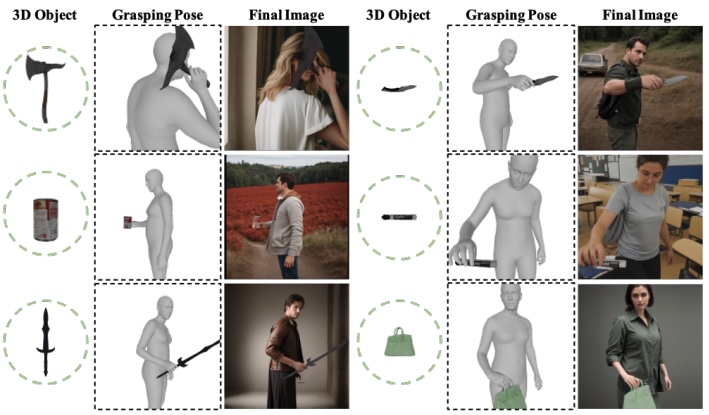
GraspDiffusion: Synthesizing Realistic Whole-body Hand-Object Interaction
Patrick Kwon, Hanbyul Joo In WACV, 2026 [Paper] |

|
Audio Driven Real-Time Facial Animation for Social Telepresence
Jiye Lee, Chenghui Li, Linh Tran, Shih-En Wei, Jason Saragih, Alexander Richard, Hanbyul Joo†, Shaojie Bai† In SIGGRAPH Asia 2025 [Paper] [Project Page] |

|
Learning to Generate Human-Human-Object Interactions from Textual Descriptions
Jeonghyeon Na*, Sangwon Baik*, Inhee Lee, Junyoung Lee, Hanbyul Joo In NeurIPS 2025 [Paper] [Project Page] |
|
Durian: Dual Reference-guided Portrait Animation with Attribute Transfer
Hyunsoo Cha, Byungjun Kim, Hanbyul Joo In preprint 2025 [Paper] [Project Page] |
|

|
DAViD: Modeling Dynamic Affordance of 3D Objects using Pre-trained Video Diffusion Models
Hyeonwoo Kim, Sangwon Baik, Hanbyul Joo In ICCV 2025 [Paper] [Project Page] |

|
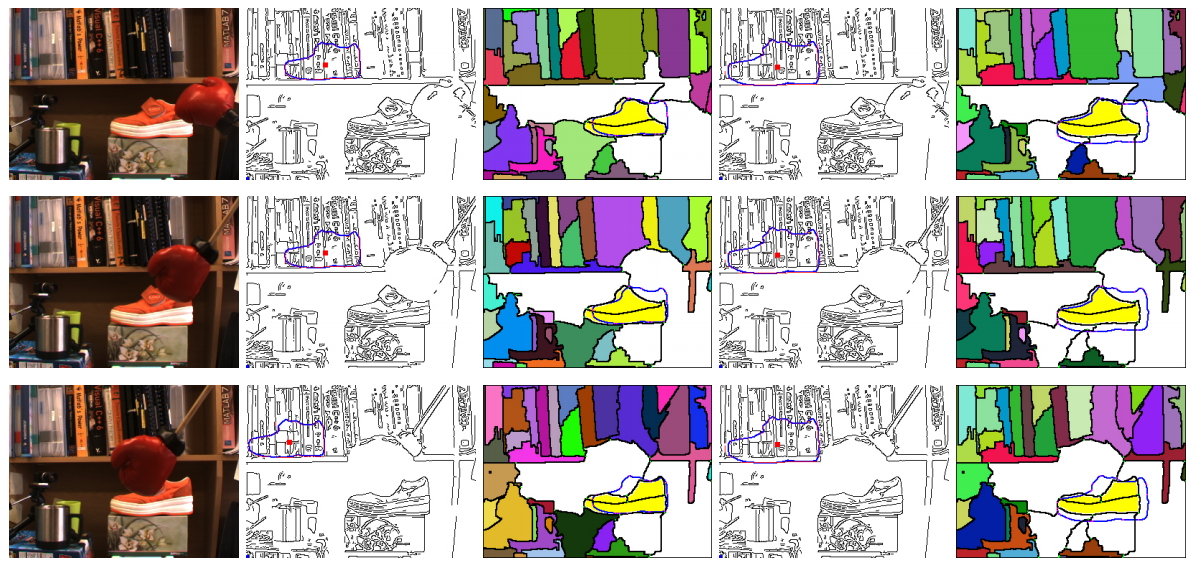
Learning 3D Object Spatial Relationships from Pre-trained 2D Diffusion Models
Sangwon Baik, Hyeonwoo Kim, Hanbyul Joo In ICCV 2025 [Paper] [Project Page] |
|
HairCUP: Hair Compositional Universal Prior for 3D Gaussian Avatars
Byungjun Kim, Shunsuke Saito, Giljoo Nam, Tomas Simon, Jason Saragih, Hanbyul Joo†, Junxuan Li† In ICCV 2025 (Oral presentation) [Paper] [Project Page] |
|
|
|
ParaHome: Parameterizing Everyday Home Activities Towards 3D Generative Modeling of Human-Object Interactions
Jeonghwan Kim*, Jisoo Kim*, Jeonghyeon Na, Hanbyul Joo In CVPR 2025 [Paper] [Project Page] [Code/Dataset] |
|
PERSE: Personalized 3D Generative Avatars from A Single Portrait
Hyunsoo Cha, Inhee Lee, Hanbyul Joo In CVPR 2025 [Paper] [Project Page] [Code] |
|
|
Target-Aware Video Diffusion Models
Taeksoo Kim, Hanbyul Joo In arxiv 2025 [Paper] [Project Page] |
|

|
Learning to Transfer Human Hand Skills for Robot Manipulations
Sungjae Park*, Seungho Lee*, Mingi Choi*, Jiye Lee, Jeonghwan Kim, Jisoo Kim, Hanbyul Joo In CORL X-Embodiment Workshop 2024 [Paper] [Project Page] |

|
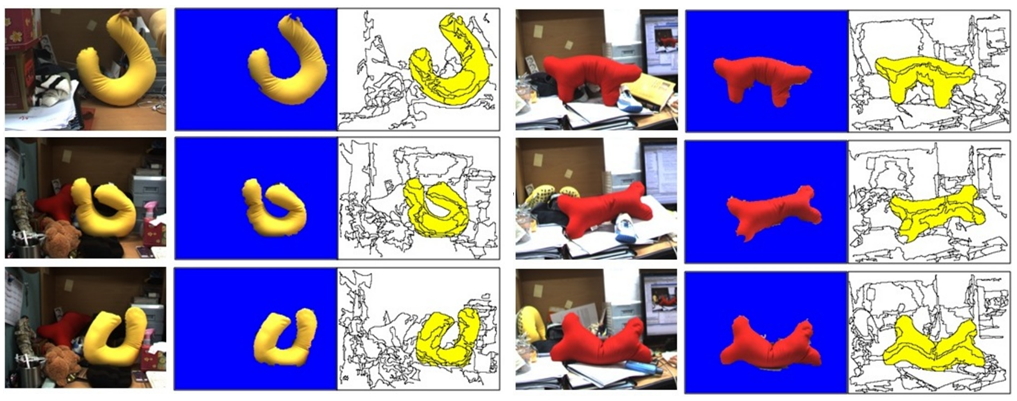
Beyond the Contact: Discovering Comprehensive Affordance for 3D Objects from Pre-trained 2D Diffusion Models
Hyeonwoo Kim*, Sookwan Han*, Patrick Kwon, Hanbyul Joo In ECCV 2024 (Oral presentation) - Acceptance ratio: 200/8585 = 2.3% [Paper] [Project Page] |

|
Guess The Unseen: Dynamic 3D Scene Reconstruction from Partial 2D Glimpses
Inhee Lee, Byungjun Kim, Hanbyul Joo In CVPR 2024 [Paper] [Project Page] [Code] |
|
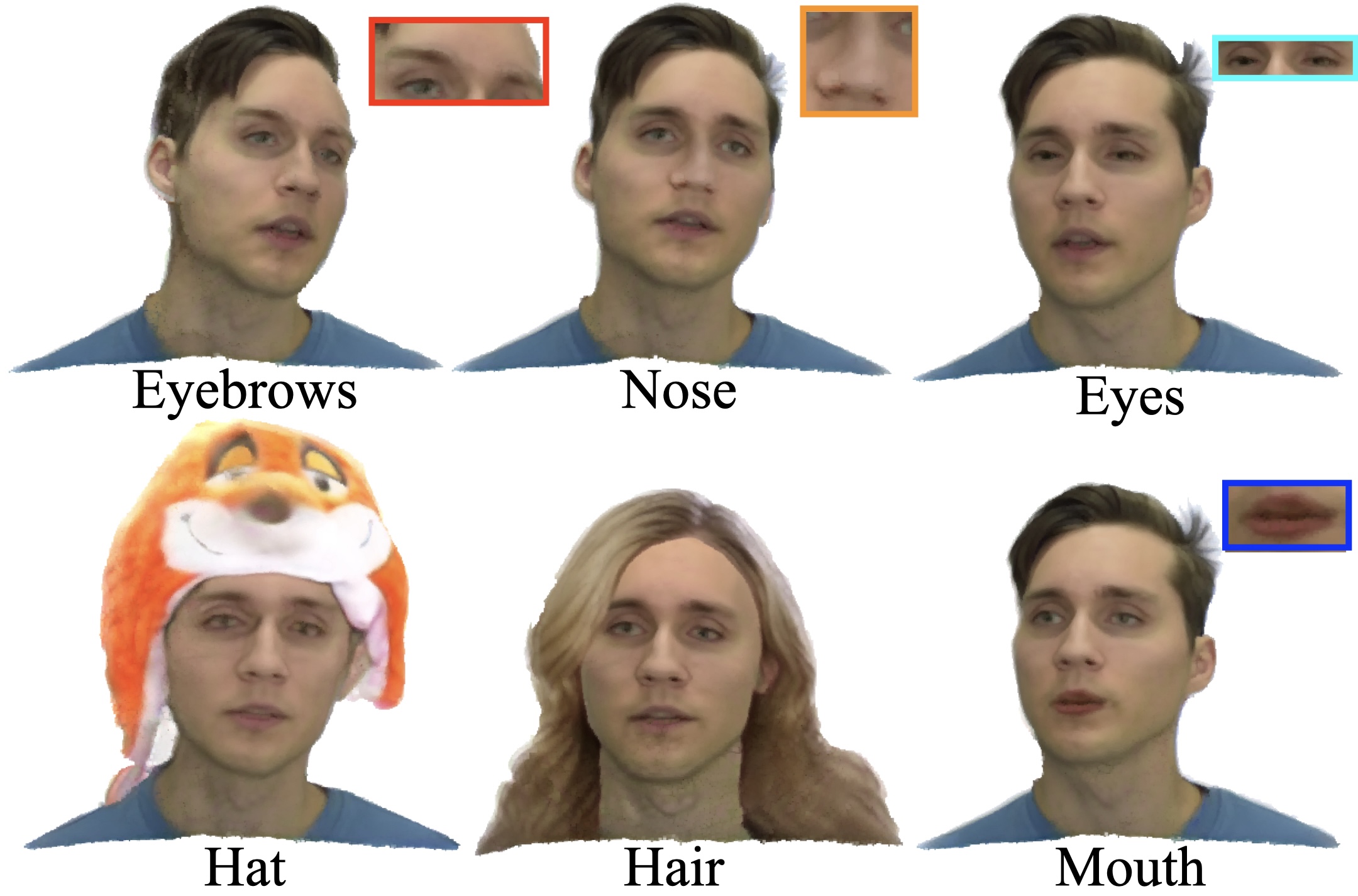
PEGASUS: Personalized Generative 3D Avatars with Composable Attributes
Hyunsoo Cha, Byungjun Kim, Hanbyul Joo In CVPR 2024 [Paper] [Project Page] [Code] |

|
GALA: Generating Animatable Layered Assets from a Single Scan
Taeksoo Kim*, Byungjun Kim*, Shunsuke Saito, Hanbyul Joo In CVPR 2024 [Paper] [Project Page] [Code] |

|
Mocap Everyone Everywhere: Lightweight Motion Capture With Smartwatches and a Head-Mounted Camera
Jiye Lee, Hanbyul Joo In CVPR 2024 [Paper] [Project Page] [Code] |

|
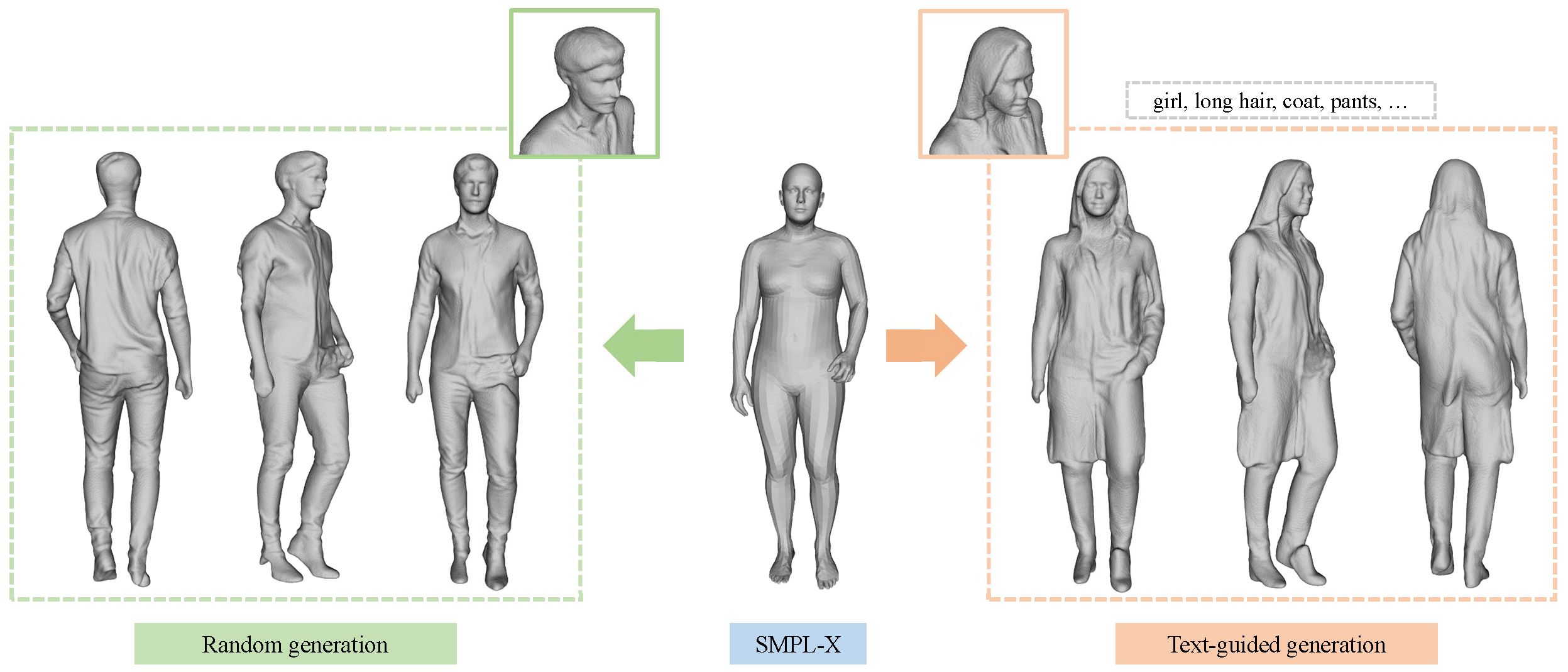
CHORUS: Learning Canonicalized 3D Human-Object Spatial Relations from Unbounded Synthesized Images
Sookwan Han, Hanbyul Joo In ICCV 2023 (Oral presentation) - Acceptance ratio: 152/8260 = 1.8% [Paper] [Project Page] [Code] |
|
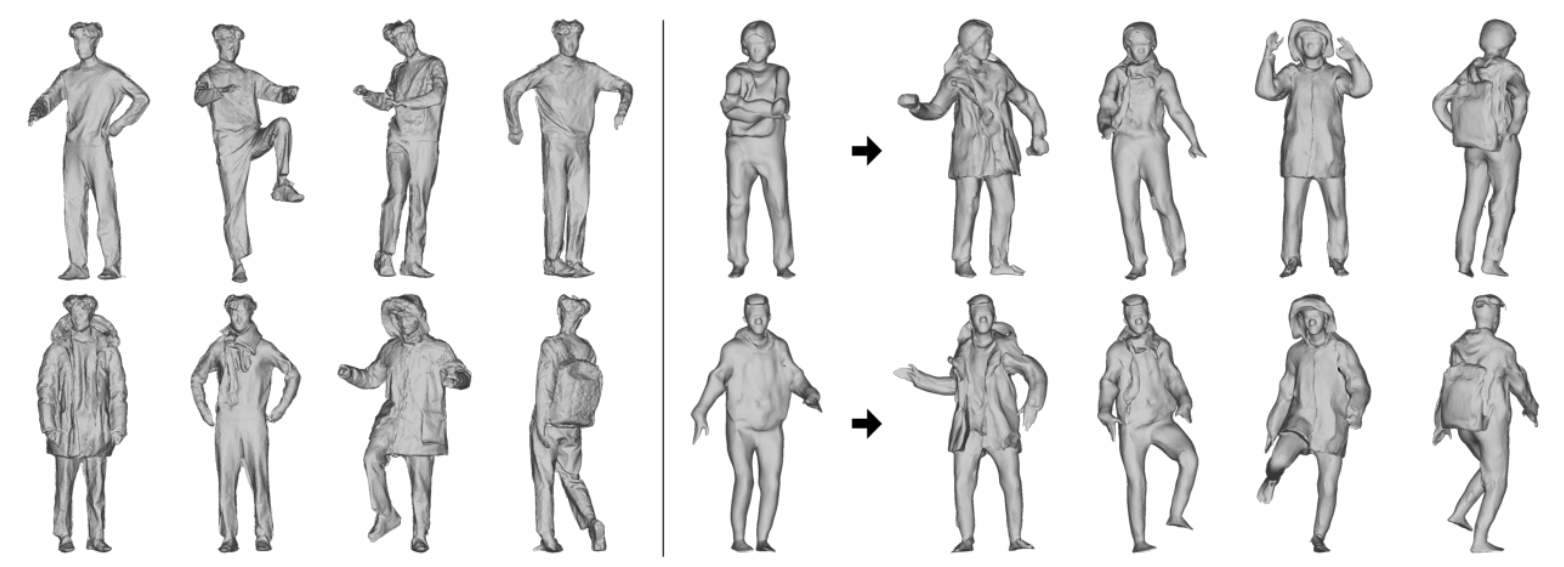
Chupa: Carving 3D Clothed Humans from Skinned Shape Priors using 2D Diffusion Probabilistic Models
Byungjun Kim*, Patrick Kwon*, Kwangho Lee, Myunggi Lee, Sookwan Han, Daesik Kim, Hanbyul Joo In ICCV 2023 (Oral presentation) - Acceptance ratio: 152/8260 = 1.8% [arxiv] [Project Page] [Code] |
|
NCHO: Unsupervised Learning for Neural 3D Composition of Humans and Objects
Taeksoo Kim, Shunsuke Saito, Hanbyul Joo In ICCV 2023 [arxiv] [Project Page] [Code] |

|
Locomotion-Action-Manipulation: Synthesizing Human-Scene Interactions in Complex 3D Environments
Jiye Lee, Hanbyul Joo In ICCV 2023 [arxiv] [Project Page] [Code] |

|
BANMo: Building Animatable 3D Neural Models from Many Casual Videos
Gengshan Yang, Minh Vo, Natalia Neverova, Deva Ramanan, Andrea Vedaldi, Hanbyul Joo In CVPR 2022 (Oral presentation) - Acceptance ratio: 344/8161 = 4.2% [arxiv] [Project Page] |
|
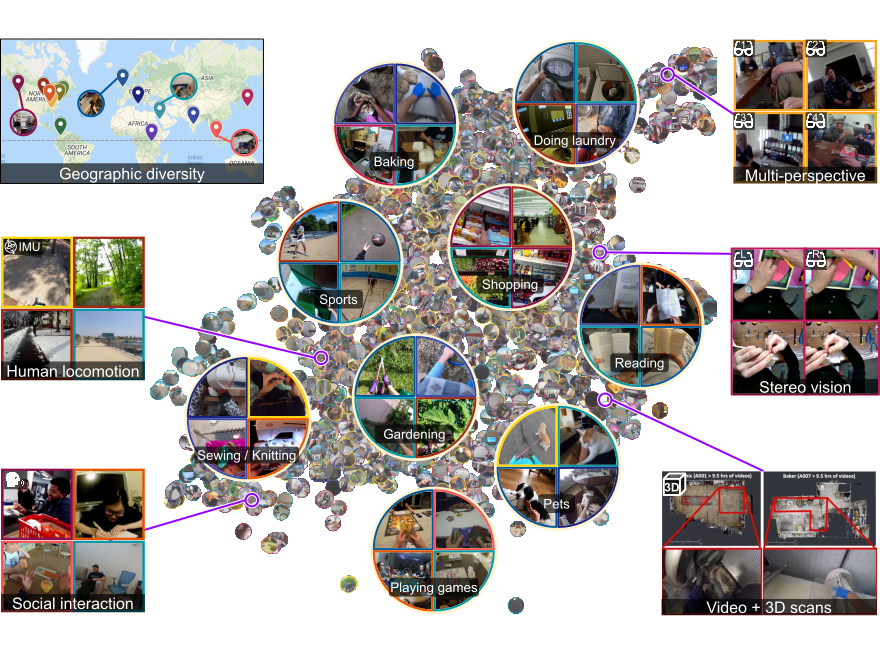
Ego4D: Around the World in 3,000 Hours of Egocentric Video
Grauman et al. In CVPR 2022 (Oral presentation) - Acceptance ratio: 344/8161 = 4.2% [Best Paper Award Finalist] [arxiv] [Project Page] |

|
Learning to Listen: Modeling Non-Deterministic Dyadic Facial Motion
Evonne Ng , Hanbyul Joo, Liwen Hu, Hao Li, Trevor Darrell, Angjoo Kanazawa, Shiry Ginosar In CVPR 2022 [arxiv] [Project Page] [Code+Data] |

|
Modeling Human Intention Inference in Continuous 3D Domains by Inverse Planning and Body Kinematics
Yingdong Qian, Marta Kryven, Tao Gao, Hanbyul Joo, Josh Tenenbaum arXiv 2021 [arxiv] |

|
D3D-HOI: Dynamic 3D Human-Object Interactions from Videos
Xiang Xu, Hanbyul Joo, Greg Mori, Manolis Savva arXiv 2021 [arxiv] [Code/Data] |

|
FrankMocap: A Fast Monocular 3D Hand and Body Motion Capture by Regression and Integration
Yu Rong, Takaaki Shiratori, Hanbyul Joo In ICCV 2021 Workshop [arxiv] [Project Page] [Code] |

|
Exemplar Fine-Tuning for 3D Human Model Fitting Towards In-the-Wild 3D Human Pose Estimation
Hanbyul Joo, Natalia Neverova, Andrea Vedaldi 3DV 2021 (Oral presentation) [arxiv] [Code/Dataset] |
|
Body2Hands: Learning to Infer 3D Hands from Conversational Gesture Body Dynamics
Evonne Ng, Shiry Ginosar, Trevor Darrell, Hanbyul Joo In CVPR 2021 [arxiv] [Project Page] |

|
3D Multi-bodies: Fitting Sets of Plausible 3D Human Models to Ambiguous Image Data
Benjamin Biggs, Seb Ehrhadt, Hanbyul Joo, Ben Graham, Andrea Vedaldi, David Novotny In NeurIPS 2020 (Spotlight) [arxiv] [Project Page] |

|
Perceiving 3D Human-Object Spatial Arrangements
from a Single Image in the Wild
Jason Y. Zhang*, Sam Pepose*, Hanbyul Joo, Deva Ramanan, Jitendra Malik, Angjoo Kanazawa In ECCV 2020 [arxiv] [Project Page] |

|
PIFuHD: Multi-Level Pixel-Aligned Implicit Function for High-Resolution 3D Human Digitization
Shunsuke Saito, Tomas Simon, Jason Saragih, Hanbyul Joo In CVPR 2020 (Oral presentation) - Acceptance ratio: 335/6424~5.2% [arxiv] [Project Page] [Code] [Colab Demo] |

|
You2Me: Inferring Body Pose in Egocentric Video via First and Second Person Interactions
Evonne Ng, Donglai Xiang, Hanbyul Joo, Kristen Grauman In CVPR 2020 (Oral presentation) - Acceptance ratio: 335/6424~5.2% [arxiv] [Project Page] [Code/Data] |

|
Single-Network Whole-Body Pose Estimation
Gines Hidalgo, Yaadhav Raaj, Haroon Idrees, Donglai Xiang, Hanbyul Joo, Tomas Simon, Yaser Sheikh In ICCV 2019 [arxiv] [OpenPose Training] [OpenPose] |
|
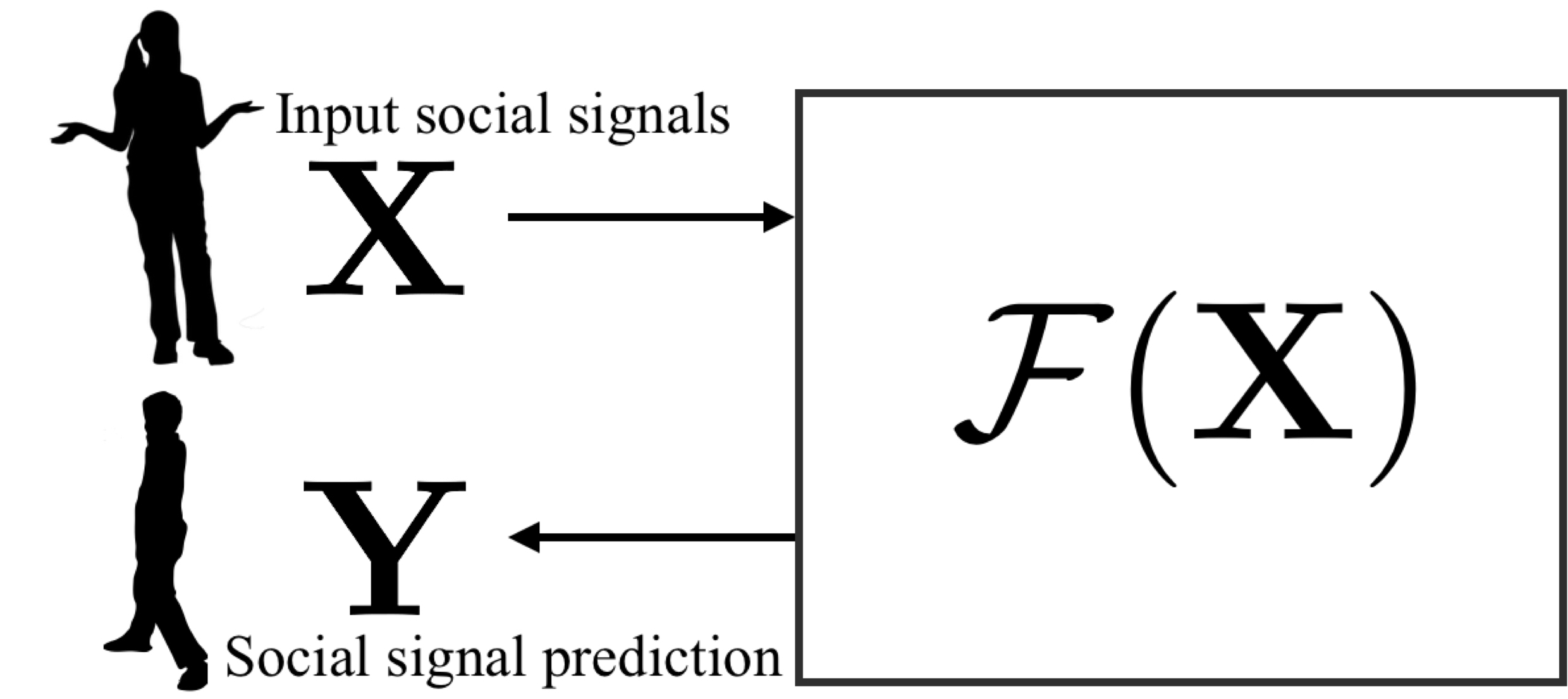
Towards Social Artificial Intelligence: Nonverbal Social Signal Prediction in A Triadic Interaction
Hanbyul Joo, Tomas Simon, Mina Cikara, Yaser Sheikh In CVPR 2019 (Oral presentation) - Acceptance ratio: 288/5165~5.5% [arxiv] [Code/Dataset] [Video] |

|
Monocular Total Capture: Posing Face, Body and Hands in the Wild
Donglai Xiang, Hanbyul Joo, Yaser Sheikh In CVPR 2019 (Oral presentation) - Acceptance ratio: 288/5165~5.5% [arxiv] [Dataset and Code] [Video] |
|
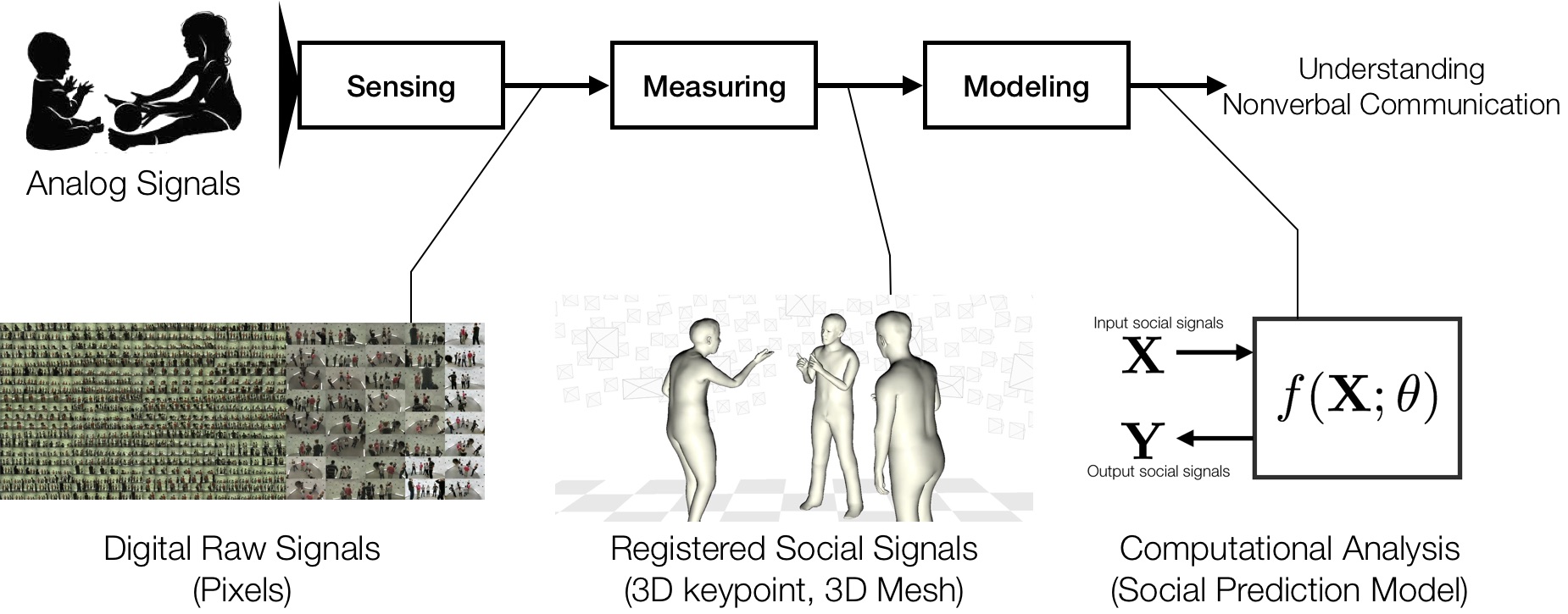
Sensing, Measuring, and Modeling Social Signals in Nonverbal Communication
Hanbyul Joo PhD Thesis, Robotics Institute, Carnegie Mellon University, 2019 [PDF] |

|
Total Capture: A 3D Deformation Model for Tracking Faces, Hands, and Bodies
Hanbyul Joo, Tomas Simon, and Yaser Sheikh In CVPR 2018 (Oral presentation) - Acceptance ratio: 70/3359~2.0% [CVPR Best Student Paper Award] [PDF] [Supplementary Material] [video] [Project Page] |

|
Structure from Recurrent Motion: From Rigidity to Recurrency
Xiu Li, Hongdong Li, Hanbyul Joo, Yebin Liu, Yaser Sheikh In CVPR 2018 [PDF] |

|
Hand Keypoint Detection in Single Images using Multiview Bootstrapping
Tomas Simon, Hanbyul Joo, Iain Mattews, and Yaser Sheikh In CVPR 2017 [arXiv] [Project Page] [Code] [Dataset] |

|
Panoptic Studio: A Massively Multiview System for Social Interaction Capture
Hanbyul Joo, Tomas Simon, Xulong Li, Hao Liu, Lei Tan, Lin Gui, Sean Banerjee, Timothy Godisart, Bart Nabbe, Iain Matthews, Takeo Kanade, Shohei Nobuhara, and Yaser Sheikh In TPAMI 2017 (Extended version of ICCV15) [published version] [arXiv version] [Dataset] |

|
Panoptic Studio: A Massively Multiview System for Social Motion Capture
Hanbyul Joo, Hao Liu, Lei Tan, Lin Gui, Bart Nabbe, Iain Matthews, Takeo Kanade, Shohei Nobuhara, and Yaser Sheikh In ICCV 2015 (Oral presentation) < Acceptance ratio: 56/1698~3.3% [Paper(PDF)] [Supplementary Material] [Project Page] Press Coverage: |

|
MAP Visibility Estimation for Large-Scale Dynamic 3D Reconstruction
Hanbyul Joo, Hyun Soo Park, and Yaser Sheikh In CVPR 2014 (Oral presentation) - Acceptance ratio: 104/1807~5.8% [Paper(PDF)] [Project Page] [Dataset] Press Coverage: |
|
Graph-based Shape Matching for Deformable Objects
Hanbyul Joo, Yekeun Jeong, Olivier Duchenne, and In So Kweon In ICIP 2011 [Paper(PDF)] |
|
Graph-Based Robust Shape Matching for Robotic Application
|
Talks
-
"Measuring and Modeling Human Motion"
- Facebook AI Video Summit, June 2019.
-
"Towards Social Artificial Intelligence: Nonverbal Social Signal Prediction in A Triadic Interaction"
- CVPR Oral Talk, June 2019 (video link).
-
"Total Capture: A 3D Deformation Model for Tracking Faces, Hands, and Bodies"
- GAMES Webinar, Oct 2018 (hosted by Prof. Yebin Liu).
- CVPR Oral Talk, June 2018 (video link).
-
"Measuring and Modeling Social Signals for Computational Behavioral Understanding"
- UC Berkeley, BAIR, MAY 2018 (hosted by Prof. Jitendra Malik).
- UT Austin, School of Computer Science, April 2018.
- CMU, School of Computer Science, April 2018.
- MIT, CSAIL, April 2018.
- MIT, Media Lab, Nov 2017.
-
"The Panoptic Studio: A Massively Multiview System for Social Interaction Capture"
- UC Berkeley, Computer Vision Group, Dec 2016 (hosted by Prof. Alexei A. Efros).
- Stanford, Computer Vision and Geometry Lab (CVGL), Dec 2016 (hosted by Prof. Silvio Savarese).
- Adobe Research, Dec 2016 (hosted by Dr. Joon-Young Lee).
- ASSP4MI workshop of ICMI, Nov 2016.
- CMU, Machine Learning Lunch Seminar, Oct 2016.
- ICCV Oral Talk, Dec 2015 (video link).
- CMU, VASC Seminar, Dec 2015.
- ETH Zurich, Computer Vision and Geometry lab, Oct 2015 (hosted by Prof. Marc Pollefeys).
- Seoul National University, June 2015 (hosted by Prof. Kyoung Mu Lee).
- ETRI, CG Team, May 2015 (hosted by Dr. Seong-Jae Lim).
- KAIST, May 2015 (hosted by Prof. In So Kweon).
-
"The Panoptic Studio (CVPR14)"
- Graduate Seminar, Civil & Environmental Engineering, CMU, Feb 2015 (hosted by Prof. Hae Young Noh).
- People Image Analysis Consortium, CMU, Nov 2014.
- Reality Computing Meetup, Autodesk, Nov 2014.
-
"MAP Visibility Estimation for Large-Scale Dynamic 3D Reconstruction"
- CVPR Oral Talk, June 2014
- CMU, VASC Seminar, June 2014.
Press Coverage
- Arirang TV, The Evolution of AI and AI: Reading Humans, 2025
- IEEE Spectrum, Robots Learn to Speak Body Language, 2017
- ZDNet, CMU researchers create a huge dome that can read body language, 2017
- TechCrunch, CMU researchers create a huge dome that can read body language, 2017
- BBC News, The dome which could help machines understand behaviour, 2017
- CMU News, Scientists put human interaction under the microscope, 2017
- SPIEGEL ONLINE(German), The panoptic Studio: Computer decipher the secrets of body language, 2015
- Co.DESIGN, Inside A Robot Eyeball, Science Will Decode Our Body Language, 2015
- WIRED (Italian) Panoptic Studio: The Latest Generation of Motion Capture, 2015
- Voice of America, New Studio Yields Most Detailed Motion Capture in 3D, 2015 (Video)
- CNet, Tomorrow Daily: New video capture tech, the Rickroll 'Rickmote,' a new X-wing, and more, 2014 (Video)
- NBCNews, Camera-Studded Dome Tracks Your Every Move With Precision, 2014
- IEEE Spectrum, Camera-Filled Dome Recreates Full 3-D Motion Scenes, 2014
- Discovery News, Amazing 3-D Flicks from Dome of 500 Cameras?, 2014
- Gizmodo, A Dome Packed With 480 Cameras Captures Detailed 3D Images In Motion, 2014
- The Verge, Scientists build a real Panopticon that captures your every move in 3D, 2014
- ScienceDaily, Hundreds of videos used to reconstruct 3-D motion without markers, 2014
- Phys.org, Researchers combine hundreds of videos to reconstruct 3D motion without markers, 2014
- Engadget, Watch a dome full of cameras capture 3D motion in extreme detail, 2014
- PetaPixel, Researchers Use a 480-Camera Dome to More Accurately Capture 3D Motion 2014
- Gizmag, Camera-studded dome used to reconstruct 3D motion, 2014
- The Register, Boffins fill a dome with 480 cameras for 3D motion capture 2014
- The Engineer, 3D motion captured without markers, 2014
- Popular Photography, Carnegie Mellon Packs 480 Cameras In A Dome To Perfectly Track 3D Motion, 2014
- CMU News, Carnegie Mellon Combines Hundreds of Videos To Reconstruct 3D Motion Without Use of Markers, 2014
 WIRED, 2018 [Video + Article] |
 Reuters, 2017 [Video] |
 The Verge, 2016 [Video, Article] |
 Reuters, 2015 [Video + Article] |
 Daily Planet, Discovery, 2015 [Video] |
 Docuprime, EBS (Korean TV), 2017 [Video] |
Patents
-
Motion capture apparatus and method (Patent No.: US 8805024 B2)
Hanbyul Joo, Seong-Jae Lim, Ji-Hyung Lee, Bon-Ki Koo -
Method for automatic rigging and shape surface transfer of 3D standard mesh model based on muscle and nurbs by using parametric control (Patent No.: US 7171060 B2)
Seong Jae Lim, Ho Won Kim, Hanbyul Joo, Bon Ki Koo 3D model shape transformation method and apparatus (Patent Application No.: US 20120162217 A1)
Seong-Jae Lim, Hanbyul Joo, Seung-Uk Yoon, Ji-Hyung Lee, Bon-Ki Koo.